分时调度¶
概述¶
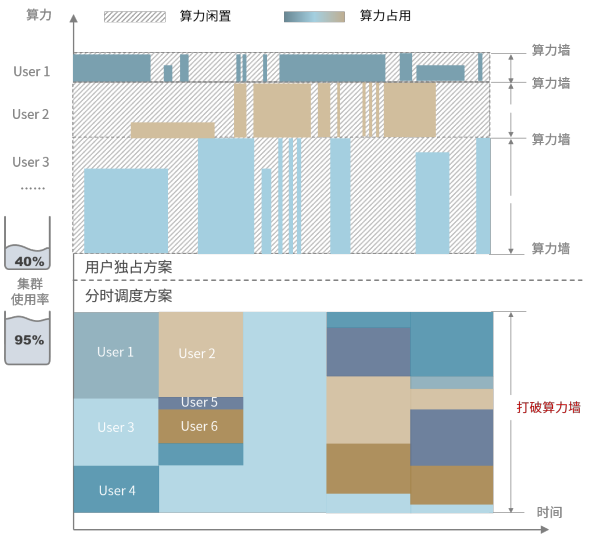
幻方萤火平台采用任务级分时调度的底层设计,给每个任务分配集群运行时间片(类似操作系统的时间片调度)。
与传统的用户独占方案相比,分时调度大幅提高了集群使用率,以此有效降低单位GPU时的使用成本;同时,分时调度较为弹性的资源占用方式,使得用户无需承担闲置算力成本,并可以根据任务需求实时增减节点配额,轻负担享受全量算力。
按照分时调度的方案规则,训练任务会被中断、并自动调起。因此在该平台上运行的代码需要遵循本页下方文档的编码要求。
调度规则¶
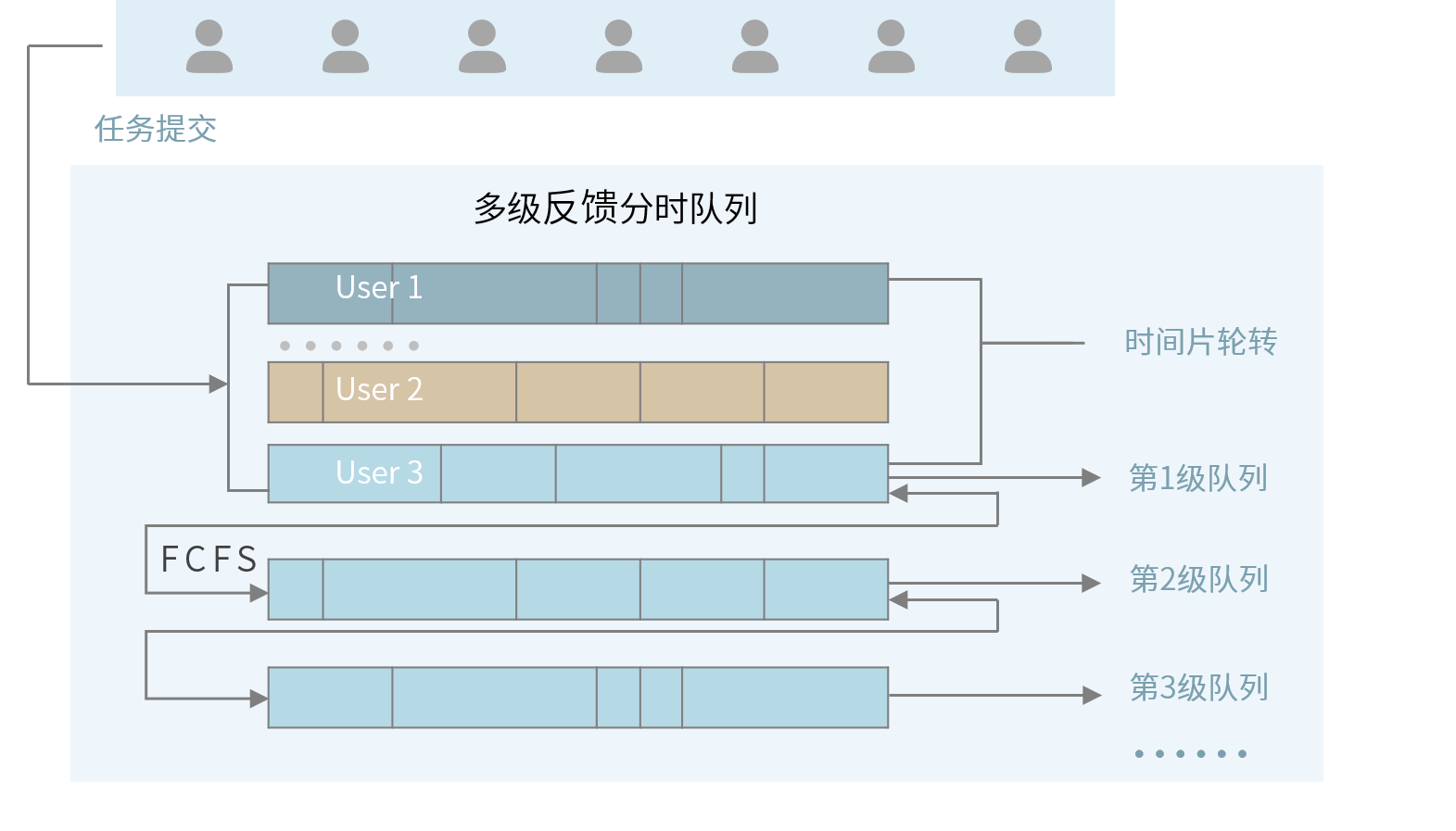
任务调度按照优先级从高到低调度任务
同一优先级按照 “先到先服务” 原则排队等待被分配时间片
对于同一用户、同优先级的任务,不会打断运行中的任务来调度另一个任务
一个
ABOVE_NORMAL的任务运行满30分钟后,自动降级为NORMAL任何任务恢复运行,都是从头执行任务代码,用户需按照编码要求进行断点编码处理
基本要素¶
任务状态¶
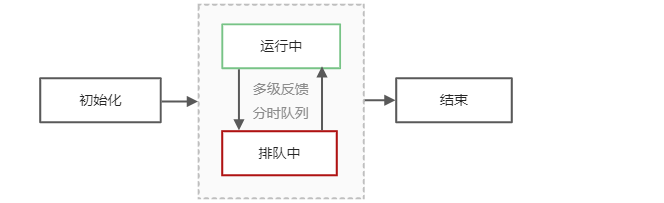
任务状态分为:等待初始化、运行、排队挂起、结束(运行成功/失败) 四种状态,流转示意图如下:
任务优先级¶
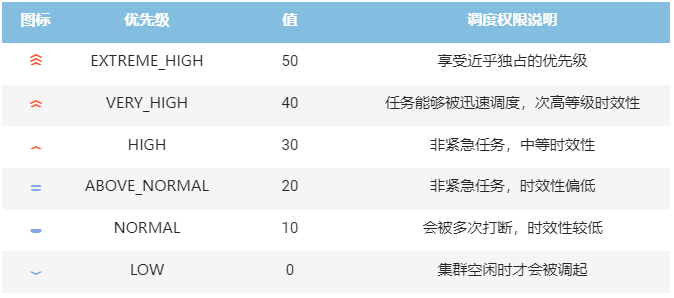
注意:上述优先级的选择为高级权限,仅供幻方内部研发使用。未授权用户默认为AUTO,接受自动优先级调配。
获取优先级配额¶
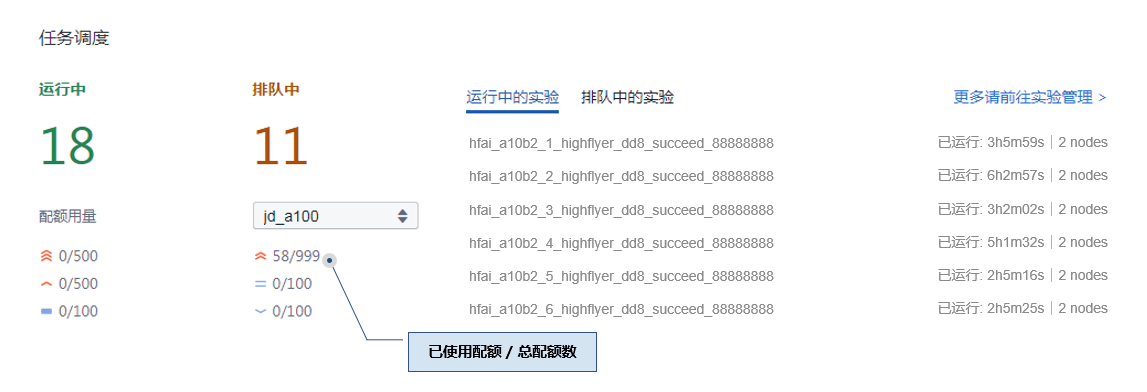
用户在每个优先级上都有节点配额,该配额数表示最多可以同时使用的节点数,参见下方调度界面样例。配额调整请联系幻方管理员。
编码要求¶
任务优雅挂起¶
所有任务都参与分时调度,因此任务必须支持断点续跑。任务挂起前,主节点会收到一个挂起命令,如果任务没有响应,过5秒会被强制挂起。可以使用以下接口实现优雅挂起:
hfai.client.receive_suspend_command() -> bool:查询是否收到了挂起的命令,返回True表示要挂起
只有主节点(Rank 0)才能收到挂起命令,且主节点的所有python子进程都能收到挂起命令,而其他节点收不到
hfai.client.go_suspend():通知调度系统可以打断,最多预留5秒进行断点的保存
任一个节点调用本函数都会导致任务被优雅挂起,本函数不返回。
下面是一个训练的代码参考:
import torch
import hfai
def main(gpu_id):
torch.cuda.set_device(gpu_id)
# 初始化模型、数据集、迭代器等
for epoch in range(epochs):
# 训练一个step
if hfai.distributed.get_rank() == 0 and gpu_id == 0: # 获取当前节点序号。在0号节点的0号进程上接收集群调度信息
if hfai.client.receive_suspend_command():
# 保存模型、迭代器等参数到文件
time.sleep(5) # 最多预留5秒完成断点保存,之后会被强制打断
hfai.client.go_suspend()
if __name__ == '__main__':
ngpus = torch.cuda.device_count()
hfai.multiprocessing.spawn(main, args=(), nprocs=ngpus, bind_numa=True)
断点续跑¶
任务接受集群的统一调度,每个被打断的任务重新拉起运行时,会从头执行运行命令。因此,为了实现模型不受打断影响持续训练,需要用户在代码中设置好断点,即做好现场的保存,实现断点续跑功能。
对于模型比较小的情况(<2GB),在并行训练中只需要指定0号进程负责模型断点的保存即可。如下例所示:
if hfai.distributed.get_rank() == 0 and gpu_id == 0 and hfai.client.receive_suspend_command():
state = {
'model': model.module.state_dict(),
'optimizer': optimizer.state_dict(),
'acc': best_acc,
'epoch': epoch,
'step': step + 1
}
torch.save(state, save_path / 'latest.pt')
time.sleep(5)
hfai.client.go_suspend()
上述代码保存了模型、迭代器的参数和训练的epoch、step,方便在下次执行时恢复当前现场。
如果您的模型规模比较大(>2GB),在单进程上无法实现5秒内完成断点的保存,您可以使用幻方AI自研的hfai.checkpoint工具。如下例所示:
model = MyModel()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
start_epoch, start_step, others = hfai.checkpoint.init(model, optimizer, ckpt_path='latest.pt')
for epoch in range(start_epoch, epochs):
for step, (x, y) in enumerate(dataloader):
if step < start_step:
continue
output = model(x)
loss_fn(y, output).backward()
model.try_save(epoch, step, others=None)
start_step = 0
hfai.checkpoint 将任务优雅挂起与模型保存进行的封装,提供简单的 try_save 接口,省去了进程的指定,方便用户使用。同时,hfai.checkpoint 提供了并行存储功能,让不同的进程各自保存模型的一部分,从而使得断点在规定时间范围内完成保存。
当然,如果您的模型规模非常巨大,hfai.checkpoint 不一定能帮您在规定时间范围内完成保存。因此,我们建议用户在每 Epoch 结束或其他什么规则下都保存一遍断点,以保证在萤火集群上训练的任务可以正常实现断点续跑。
分布式训练¶
在幻方萤火平台上每个任务最少使用8张卡,推荐使用torch.distributed框架进行多机多卡分布式训练,充分利用集群的计算资源,详情参考技术博客《PyTorch 分布式训练方法》。
平台在启动每个任务时会设置如下环境变量:
MASTER_IP: 我们规定 rank 0 为主节点,该环境变量为主节点的 IP;MASTER_PORT:主节点用于通讯的端口,初始值为 2222;WORLD_SIZE:标记当前任务总共有几个节点的环境变量;RANK:标记当前节点是第几号节点的环境变量。
以此发起分布式训练。更多完整训练案例,可以参考模型仓库