hfreduce 性能测试¶
hfreduce 是幻方 AI 自研的高速模型并行训练工具,是幻方萤火二号计算存储分离后,计算服务中的重要一环,根据萤火二号的集群特性专为计算节点设计的 allreduce 工具。 本质上 hfreduce 相当于 PyTorch 中的 DistributedDataParallel(DDP),只不过使用 CPU 做加法运算以计算总梯度,而不是调用其他的集体通信库(CCL),比如说 NCCL,传递梯度到不同的显卡上,再各自计算总梯度。
本文将对 hfreduce 的进行简要介绍,并展示其优异的性能。更多信息可以参考官方技术博客:https://www.high-flyer.cn/blog/hf-reduce/
hfreduce简介¶
幻方的主要 AI 场景是金融行为分析、自然语言处理、生物分子结构预测等。在这些场景中,基本是数据规模大而模型大小适中。换句话说,在 A100 显卡 40G 的显存中,完全可以装得下一个完整的模型和批次样本数据。因此,模型的加速主要是依赖大量的数据并行,让尽可能多的显卡参与训练,再同步梯度。
正是因为上述数据并行的应用场景,随着集群规模不断变大,我们发现,使用 NCCL 进行多 GPU 之间的集体通信,梯度信息多次在 PCIe 上遍历就会成为一个性能瓶颈。
因此,幻方 AI 放弃了 NCCL,把梯度数据都先拷贝到主内存里然后在 CPU 上做加法运算,进而计算总梯度,因为这样可以避免梯度数据在多个 GPU 之间进行多次拷贝。hfreduce 首先从所有并行的 GPU 里一次性收集梯度信息,然后在 CPU 里进行 reduce 计算,完成后将计算出来的梯度一次性广播到所有 GPU,从而将 PCIe 流量减半。如下示意图所示:
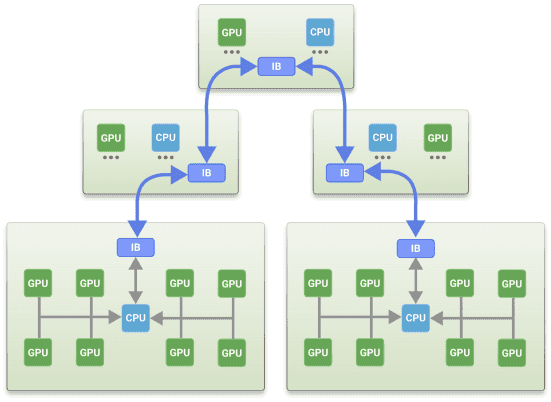
性能测试¶
那么,幻方 AI 设计的 hfreduce 方法具体能达到多少的加速效果呢?这里,我们使用 PyTorch 内嵌的 Bert 模型进行实验,测试 hfreduce 与 NCCL 的性能表现(训练耗时)。 这里 hfreduce 用接口 hfai.nn.parallel.DistributedDataParallel 去实现,而 NCCL 用 Pytorch 中的 torch.nn.parallel.DistributedDataParallel 去实现。
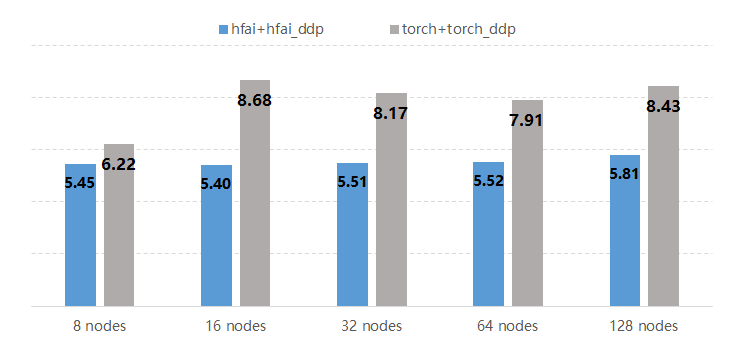
如上图所示,hfreduce 整体耗时更少,明显比没有 NVLink 的 NCCL 更快,平均提速在 25% 以上。使用 PyTorch 进行模型训练,即使在后台使用 PyTorch DDP 调用 NCCL 进行 All Reduce,hfreduce 仍然能胜过NCCL。