hfai 算子性能测评¶
深度学习框架的流行(如 PyTorch,Tensorflow 等)极大方便了我们研发设计各种各样的 AI 模型,而在实际落地的环节中,孵化于实验室里的模型代码往往在生产环境上面临着性能、准确度、资源等各种各样的问题。随着 AI 与现实世界的业务结合愈加密切,高性能且易使用的深度学习算子愈发受到 AI 研究者和开发者们的青睐。
幻方 AI 依托萤火二号集群,对 PyTorch 框架进行了深度优化,结合萤火集群的特点,对一些常用的 AI 算子重新研发,提升效率,进一步提升了模型整体的训练效率。
本文将对 hfai.nn 的各项算子进行测试,展示幻方AI优化的深度学习算子的性能。
hfai.nn.to_hfai/to_torch¶
使用方法非常简单,幻方 AI 提供了工具可以一行代码进行算子的切换,即 to_hfai 和 to_torch。
to_hfai¶
to_hfai 是方便一键使用 hfai 算子的工具,会对你的 model 进行一次深度遍历,将其中能做转化 Module 替换成 hfai 的。转化后的算子在 training 以及 inference 的时候都会有可观的性能提升。
to_torch¶
to_torch 是将使用 hfai 算子的 model 转化回使用 torch 算子的工具,以便在非 hfai 下使用训练出来的模型。设计思路同 to_hfai。
测试模型¶
我们选用 bert 模型进行测试,测试源码在此。
from hfai.nn import to_hfai, to_torch
# get model from hfai && to_hfai
model = Bert(...)
model = to_hfai(model)
性能测试¶
那么,幻方 AI 优化的算子具体能达到多少的加速效果呢?这里,我们把性能测试数据给出:
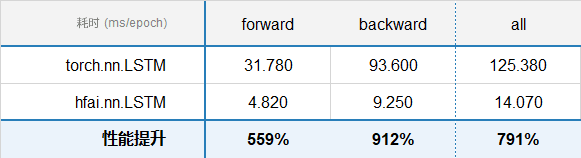
LSTM¶
参数配置:
input_size: 985
hidden_size: 985
bias: True
num_layers: 1
batch_first: True
dropout: 0
bidirectional: False
batch_size: 4
seq_len: 1000
连续测试 10 轮,统计整体每轮的耗时,测试结果如下:
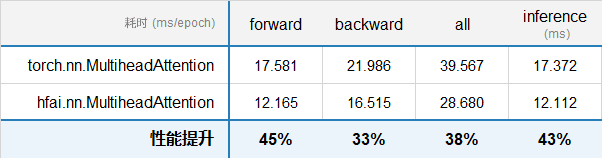
Attention¶
参数配置:
batch_size: 200
seq_len: 256
embed_dim: 1024
attn_heads: 16
连续测试 10 轮,统计 forward,backward,还有 inference 的耗时,测试结果如下:
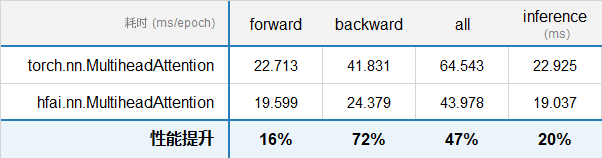
同时,当 batch_size 比较大,seq_len 比较小,以及输入 qkv 一样的情况下,hfai.nn.MultiheadAttention 同样具备优异性能。
参数配置:
batch_size: 5000
seq_len: 64
embed_dim: 512
attn_heads: 8
连续测试 10 轮,统计 forward,backward,还有 inference 的耗时,测试结果如下:
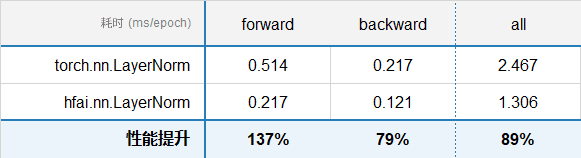
LayerNorm¶
参数配置
batch_size = 200
seq_len = 128
hidden_size = 1024
连续测试 10 轮,统计 forward,backward,还有 inference 的耗时,测试结果如下: